Introduction to Flux
Table of contents
- Basic Flux Concepts
- Flux is a Functional Language
- Declarative
- Flux Is Strongly And Statically Typed
- Flux Objects Are Immutable
- Flux Parameters Are Named
- Flux Parameter Types Can Be Overloaded
- Pipe Forwarding
- Flux Operates on Streams of Tables
- Flux Supports Looping with Map Semantics
- Dot vs. Bracket Notation
- Packages
- Further Reading
Basic Flux Concepts
Flux is the native language of InfluxDB 2.0. Flux is used for:
- Writing queries to retrieve data.
- Transforming and shaping data as needed.
- Integrating with other data sources.
Flux is a functional language designed specifically to work with the InfluxDB data format. To get the most power out of Flux, it is very useful to understand the underlying InfluxDB data model and how it relates to your schema, so make sure to read and understand the section on designing your schema above.
In the previous section, you were exposed to “just enough” Flux, but there are some important flux concepts that are useful to understand.
Flux is a Functional Language
Flux is a functional language from the ground up. Most Flux code that you write is essentially creating and linking together functions. Functions can be explicitly named, or as often as not, anonymous, meaning you declare the function inline without naming it.
Earlier, we were introduced to a filter.
|> filter(fn: (r) => r._measurement == "measurement1")
filter() is a function that itself takes a function as an argument. However, most commonly, the function for a filter is defined inline and supplied anonymously. Alternatively you could name the filter and use the filter name:
afilter_function = (r) => r._measurement == "measurement1"
from(bucket: "bucket1")
|> filter(fn: afilter_function)
We can zero in a bit on the function afilter_function and tease apart the components a bit more.
Because Flux is a functional language, functions are first class objects. So the first step is to specify the identifier (“afilter_function”) and the assignment operator (“=”). The next part is the parameter list, in this case a simple “r”, for row. Followed by the lambda operator(“ =>”). Finally, the function body itself.
afilter_function = (r) => r._measurement == "measurement1"
A function body can be multiline, which is handled syntactically as such:
afilter_function = (r) => r._measurement == "measurement1"
and r._field == "field1"
Declarative
Flux is a declarative language. This means that your Flux is executed to accomplish the expressed goal in the Flux code, and is not necessarily done in the specific manner that you specify. This boils down to the Flux execution engine applying a planner to optimize the order of operations that you have specified to achieve better performance. You will always get the results that you are asking for, but Flux may achieve them slightly differently than the specific manner in which you specified.
This will be covered in more depth in the section on optimization Flux.
Flux Is Strongly And Statically Typed
The Flux language is strongly typed. However, the typing is implicit. While you do not need to declare the types of your objects, the types are inferred when your program is run, and type mismatches cause errors.
Additionally, you cannot change the type of an object in Flux at run time. The type of an object is immutable.
Flux Objects Are Immutable
The value of an object is also immutable. For example:
astring = "hi"
astring = "bye"
Will result in an error:
@2:1-2:18: variable "astring" reassigned
Note that data in tables is NOT immutable. This will be covered in depth in the section on transforming data.
Flux Parameters Are Named
With the exception of tables passed through the pipe forward operator, all Flux parameters are named. This makes your Flux code somewhat more self documenting, but also allows for more non-breaking changes to the Flux language.
Flux Parameter Types Can Be Overloaded
In many cases, a single parameter can accept arguments of multiple types. This is covered in detail in the case of the range() section in the next section.
Pipe Forwarding
Flux is designed to transform data by piping the data between functions, each function transforming the data in turn. The operator for this is the pipe forward operator “|>”.
So you can see the following code starts with a from(), and then pipe forwards the results of that from to range().
from(bucket: "bucket1")
|> range(start: -5m)
That can then be pipe forwarded into more functions, for example, filter():
from(bucket: "bucket1")
|> range(start: -5m)
|> filter(fn: (r) => r._measurement == "measurement1")
As discussed above, a function body is defined with a set of parameters, the lambda operator, and the function operations. Additionally, when calling a function, all parameters are required named parameters. However, pipe forwarding has an implicit argument being passed between the functions, which is the stream of tables that was modified by the previous function.
A function that can be to the right of the pipe forward operator declares this with a special designation in its parameter list, the “pipe receive literal.”
(tables=<-)
So, a function body that accepts pipe forwarded data looks like this:
functionName = (tables=<-) => tables |> functionOperations
A practical example is the application of a set of common filters:
afilter_function = (tables=<-) =>
filter(fn: (r) => r._measurement == "measurement1")
filter(fn: (r) => r._field == "field1")
filter(fn: (r) => r._value > 80.0)
from(bucket: "bucketa")
|> range(start: -5m)
|> afilter_function()
Flux Operates on Streams of Tables
The consequence of the pipe forward operator is that Flux functions operate on every row of every table applied to them. To review, as you write data to InfluxDB, it is written to the storage engine in separate tables, each with a unique combination of the measurement, tag value combination, and fields. When you query that data back, those tables are read and streamed to flux, and each row of each table is then passed through each function.
You cannot ask Flux to operate on one table, but not others. Nor can you ask Flux to operate on one row, but not others. Every row in every table will undergo the same transformations.
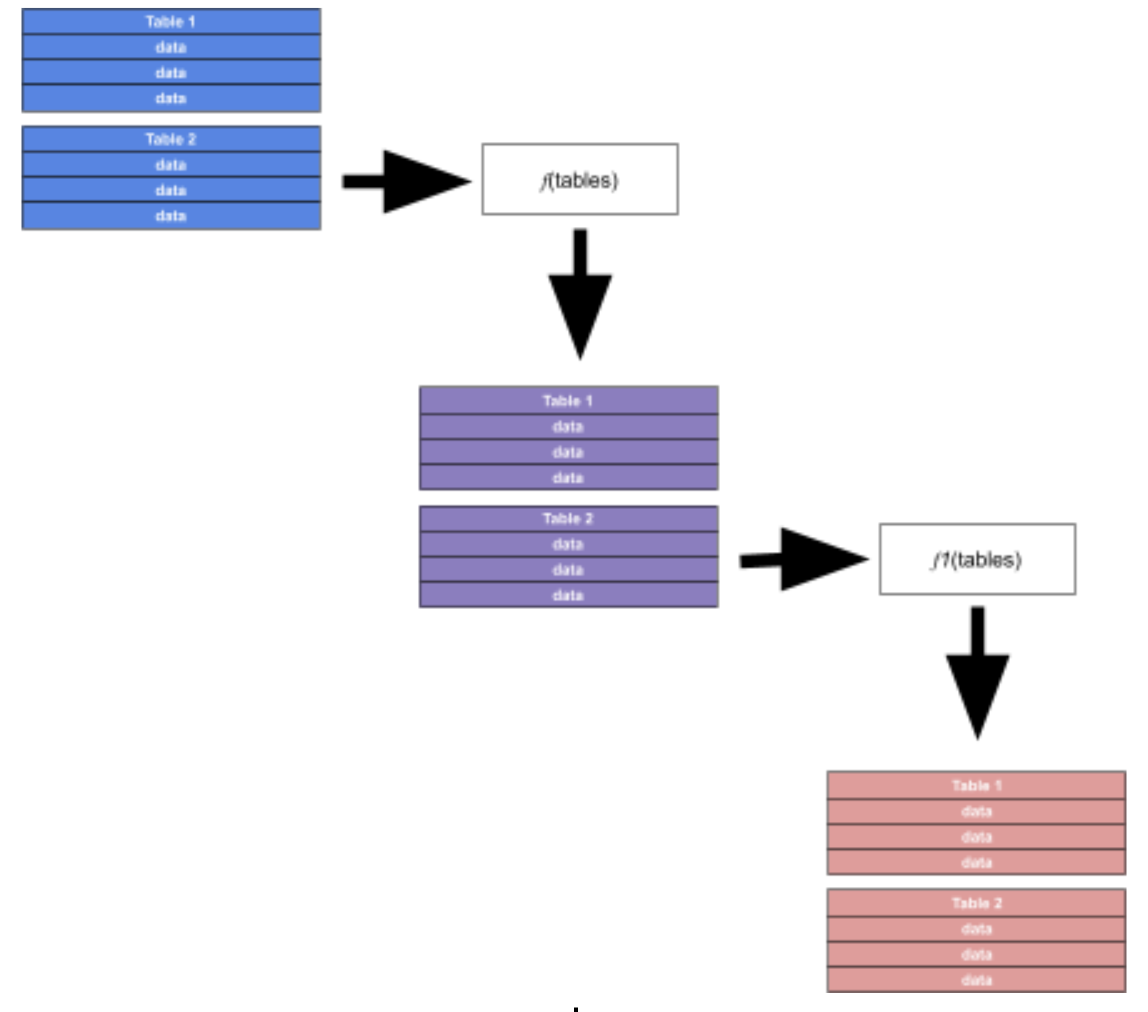
Flux Supports Looping with Map Semantics
Traditional languages support looping constructs using things like for loops, etc…. Flux uses map() to achieve the aims of loops in other languages, by applying a function to each row of each table in a stream.
Dot vs. Bracket Notation
Because Flux takes inspiration from javascript, Flux supports both dot notation and bracket notation to access members. The following 2 lines are equivalent.
filter(fn: (r) => r._measurement == "measurement1")
filter(fn: (r) => r["_measurement"] == "measurement1")
There is no official convention to determine which to use, and both are equally valid. However, generated code often uses the bracket notation because if the generated code is based on user supplied data, there is a chance that the data itself has characters that can cause syntax errors. For example, if I generate a tag that includes a period, such as sensor.001, generated code that used dot notation will be broken:
filter(fn: (r) => r.sensor.001 == "astring")
vs.
filter(fn: (r) => r["sensor.001"] == "astring")
The first line would be a syntax error, so code generators typically would produce the second one.
Packages
Flux comes with a large library of functions. These functions are organized into packages, collectively under the stdlib.
Built In Functions
The stdlib comes with a set of “built-in functions,” meaning that you can use them without importance. These are the most commonly used functions, and all the functions introduced so far (from(), range(), and filter()) are built-in.
Imports
Other packages are designed for use with more specific domains, and must be imported in order to be used. So, for example, if you wanted to work with CSV within your flux function, you would need to import the csv package, like so:
import "csv"
After which, functions in the csv package can be accessed with dot notation:
csv.from(csv: csvData, mode: "raw")
Bracket notation is also supported, which you may see occasionally:
csv["from"](csv: csvData, mode: "raw")
Here’s a minimal example of importing the csv package and calling a function from it:
import "csv"
csvData = "value,key\n1,a"
csv.from(csv: csvData, mode: "raw")
|> yield()